Real Estate Price Prediction using Python
Real Estate Price Prediction is the process of estimating or forecasting the future prices of real estate properties, such as houses, apartments, or commercial buildings. The goal is to provide accurate property rates to buyers, sellers, investors, and real estate professionals to make informed decisions about real estate transactions. If you want to learn how to predict real estate prices, this article is for you. In this article, I’ll take you through the task of Real Estate Price Prediction with Machine Learning using Python.
Real Estate Price Prediction: Process We Can Follow
Below is the process we can follow for real estate price prediction to help individuals and businesses make informed decisions in the real estate market:
- Gather relevant data from various sources, including real estate databases, government records, online listings, and other public or private sources.
- Clean and prepare the collected data by handling missing values, removing outliers, and converting categorical variables into numerical representations.
- Create new features or transform existing ones to capture important information that can influence real estate prices.
- Explore and visualize the data to gain insights into its distribution, correlations, and patterns.
- Choose appropriate machine learning algorithms or predictive models for the task.
- Train the selected model on the training data, optimizing its parameters to make accurate predictions.
For the task of Real Estate Price Prediction, we need historical data with various features that can influence property prices. I found an ideal dataset for this task. You can download the dataset from here.
Real Estate Price Prediction using Python
Now, let’s get started with the task of real estate price prediction by importing the necessary Python libraries and the dataset:
import pandas as pd
# Load the dataset
real_estate_data = pd.read_csv("/content/Real_Estate.csv")
# Display the first few rows of the dataset and the info about the dataset
real_estate_data_head = real_estate_data.head()
data_info = real_estate_data.info()
print(real_estate_data_head)
print(data_info)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 414 entries, 0 to 413
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Transaction date 414 non-null object
1 House age 414 non-null float64
2 Distance to the nearest MRT station 414 non-null float64
3 Number of convenience stores 414 non-null int64
4 Latitude 414 non-null float64
5 Longitude 414 non-null float64
6 House price of unit area 414 non-null float64
dtypes: float64(5), int64(1), object(1)
memory usage: 22.8+ KB
Transaction date House age Distance to the nearest MRT station \
0 2012-09-02 16:42:30.519336 13.3 4082.0150
1 2012-09-04 22:52:29.919544 35.5 274.0144
2 2012-09-05 01:10:52.349449 1.1 1978.6710
3 2012-09-05 13:26:01.189083 22.2 1055.0670
4 2012-09-06 08:29:47.910523 8.5 967.4000
Number of convenience stores Latitude Longitude \
0 8 25.007059 121.561694
1 2 25.012148 121.546990
2 10 25.003850 121.528336
3 5 24.962887 121.482178
4 6 25.011037 121.479946
House price of unit area
0 6.488673
1 24.970725
2 26.694267
3 38.091638
4 21.654710
None
The dataset contains 7 columns. Here’s a brief overview of the columns:
- Transaction date: The date of the real estate transaction.
- House age: Age of the house in years.
- Distance to the nearest MRT station: Distance to the nearest Mass Rapid Transit station in meters.
- Number of convenience stores: Number of convenience stores in the vicinity.
- Latitude: Latitude of the property location.
- Longitude: Longitude of the property location.
- House price of unit area: House price of unit area.
Now, let’s have a look if the data contains any null values or not:
print(real_estate_data.isnull().sum())Transaction date 0
House age 0
Distance to the nearest MRT station 0
Number of convenience stores 0
Latitude 0
Longitude 0
House price of unit area 0
dtype: int64
There are no null values in the dataset. Now, let’s have a look at the descriptive statistics of the dataset:
# Descriptive statistics of the dataset
descriptive_stats = real_estate_data.describe()
print(descriptive_stats)House age Distance to the nearest MRT station \
count 414.000000 414.000000
mean 18.405072 1064.468233
std 11.757670 1196.749385
min 0.000000 23.382840
25% 9.900000 289.324800
50% 16.450000 506.114400
75% 30.375000 1454.279000
max 42.700000 6306.153000
Number of convenience stores Latitude Longitude \
count 414.000000 414.000000 414.000000
mean 4.265700 24.973605 121.520268
std 2.880498 0.024178 0.026989
min 0.000000 24.932075 121.473888
25% 2.000000 24.952422 121.496866
50% 5.000000 24.974353 121.520912
75% 6.750000 24.994947 121.544676
max 10.000000 25.014578 121.565321
House price of unit area
count 414.000000
mean 29.102149
std 15.750935
min 0.000000
25% 18.422493
50% 30.394070
75% 40.615184
max 65.571716
Now, let’s have a look at the histograms of all the numerical features:
import matplotlib.pyplot as plt
import seaborn as sns
# Set the aesthetic style of the plots
sns.set_style("whitegrid")
# Create histograms for the numerical columns
fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(12, 12))
fig.suptitle('Histograms of Real Estate Data', fontsize=16)
cols = ['House age', 'Distance to the nearest MRT station', 'Number of convenience stores',
'Latitude', 'Longitude', 'House price of unit area']
for i, col in enumerate(cols):
sns.histplot(real_estate_data[col], kde=True, ax=axes[i//2, i%2])
axes[i//2, i%2].set_title(col)
axes[i//2, i%2].set_xlabel('')
axes[i//2, i%2].set_ylabel('')
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()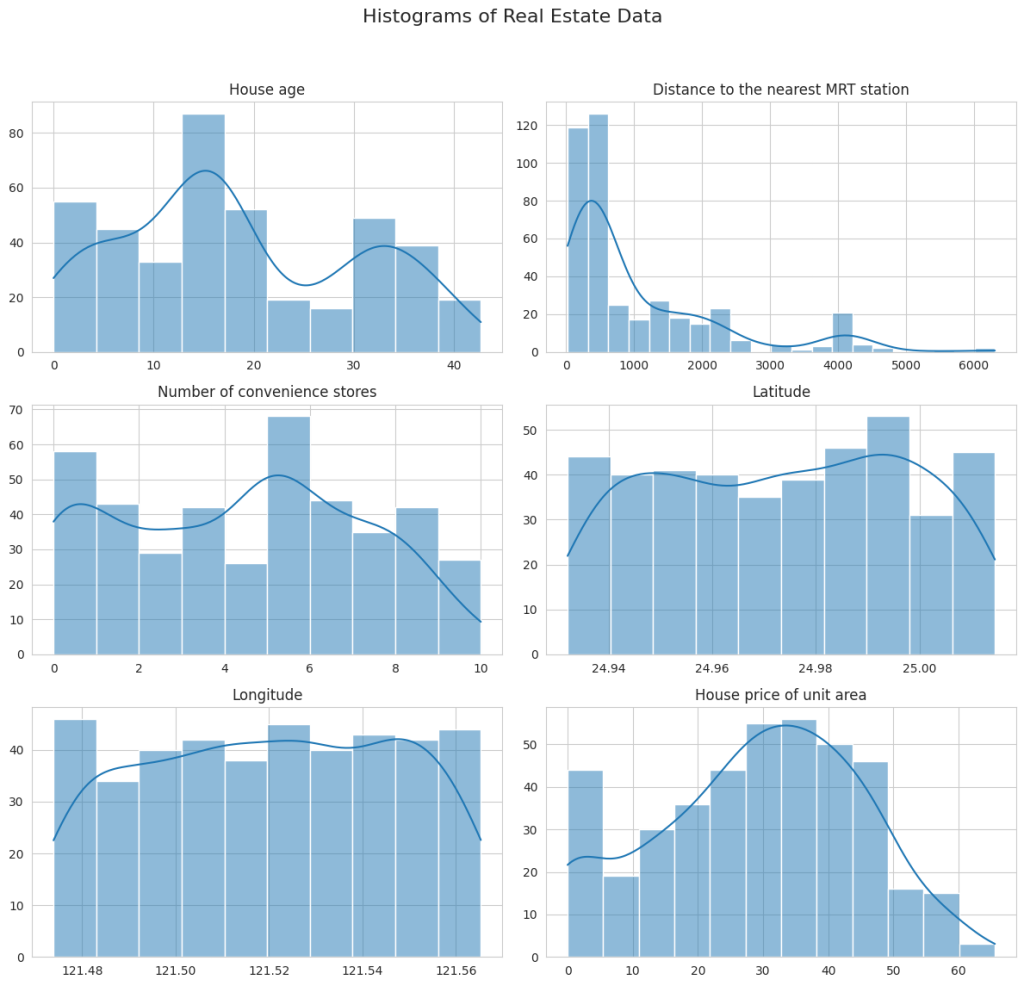
The histograms provide insights into the distribution of each variable:
- House Age: This shows a relatively uniform distribution with a slight increase in the number of newer properties (lower age).
- Distance to the Nearest MRT Station: Most properties are located close to an MRT station, as indicated by the high frequency of lower distances. There’s a long tail extending towards higher distances, suggesting some properties are quite far from MRT stations.
- Number of Convenience Stores: Displays a wide range, with notable peaks at specific counts, like 0, 5, and 10. It suggests certain common configurations in terms of convenience store availability.
- Latitude and Longitude: Both show relatively concentrated distributions, indicating that the properties are located in a geographically limited area.
- House Price of Unit Area: Displays a right-skewed distribution, with a concentration of properties in the lower price range and fewer properties as prices increase.
Next, I’ll create scatter plots to explore the relationships between these variables and the house price. It will help us understand which factors might be influencing property prices more significantly:
# Scatter plots to observe the relationship with house price
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12, 10))
fig.suptitle('Scatter Plots with House Price of Unit Area', fontsize=16)
# Scatter plot for each variable against the house price
sns.scatterplot(data=real_estate_data, x='House age', y='House price of unit area', ax=axes[0, 0])
sns.scatterplot(data=real_estate_data, x='Distance to the nearest MRT station', y='House price of unit area', ax=axes[0, 1])
sns.scatterplot(data=real_estate_data, x='Number of convenience stores', y='House price of unit area', ax=axes[1, 0])
sns.scatterplot(data=real_estate_data, x='Latitude', y='House price of unit area', ax=axes[1, 1])
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()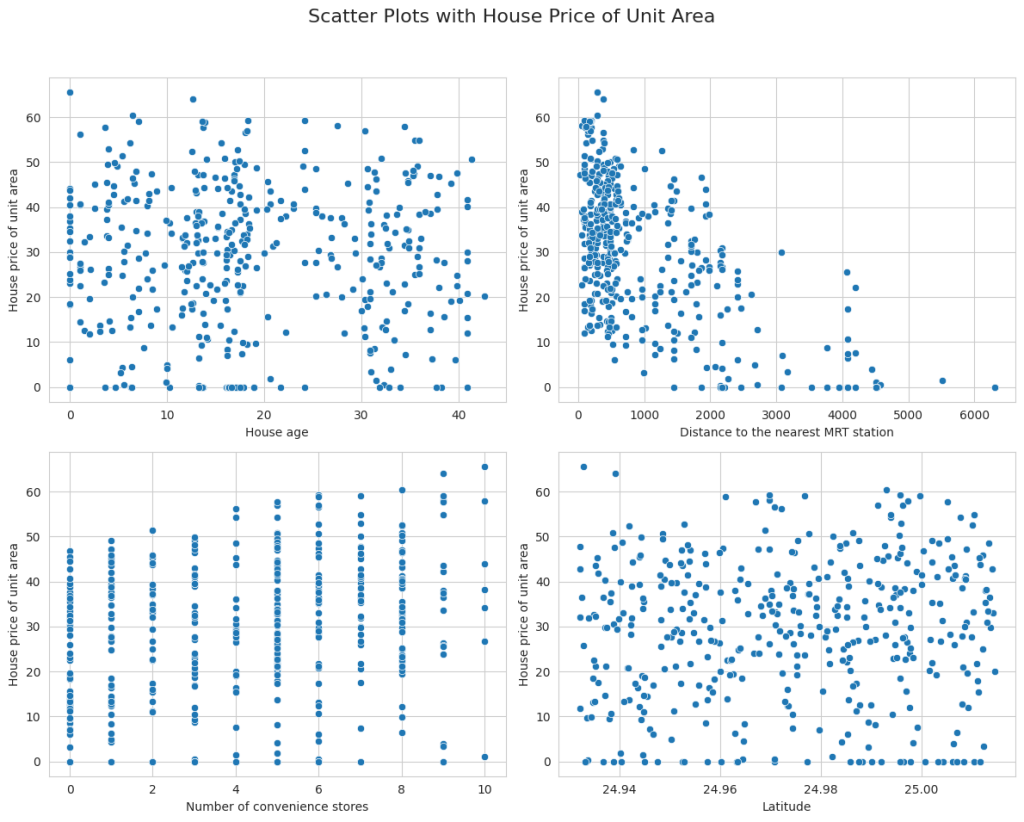
The scatter plots revealed interesting relationships between various factors and house prices:
- House Age vs. House Price: There doesn’t seem to be a strong linear relationship between house age and price. However, it appears that very new and very old houses might have higher prices.
- Distance to the Nearest MRT Station vs. House Price: There is a clear trend showing that as the distance to the nearest MRT station increases, the house price tends to decrease. It suggests a strong negative relationship between these two variables.
- Number of Convenience Stores vs. House Price: There seems to be a positive relationship between the number of convenience stores and house prices. Houses with more convenience stores in the vicinity tend to have higher prices.
- Latitude vs. House Price: While not a strong linear relationship, there seems to be a pattern where certain latitudes correspond to higher or lower house prices. It could be indicative of specific neighbourhoods being more desirable.
Finally, it would be beneficial to perform a correlation analysis to quantify the relationships between these variables, especially how each one correlates with the house price:
# Correlation matrix
correlation_matrix = real_estate_data.corr()
# Plotting the correlation matrix
plt.figure(figsize=(10, 6))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f", linewidths=.5)
plt.title('Correlation Matrix')
plt.show()
print(correlation_matrix)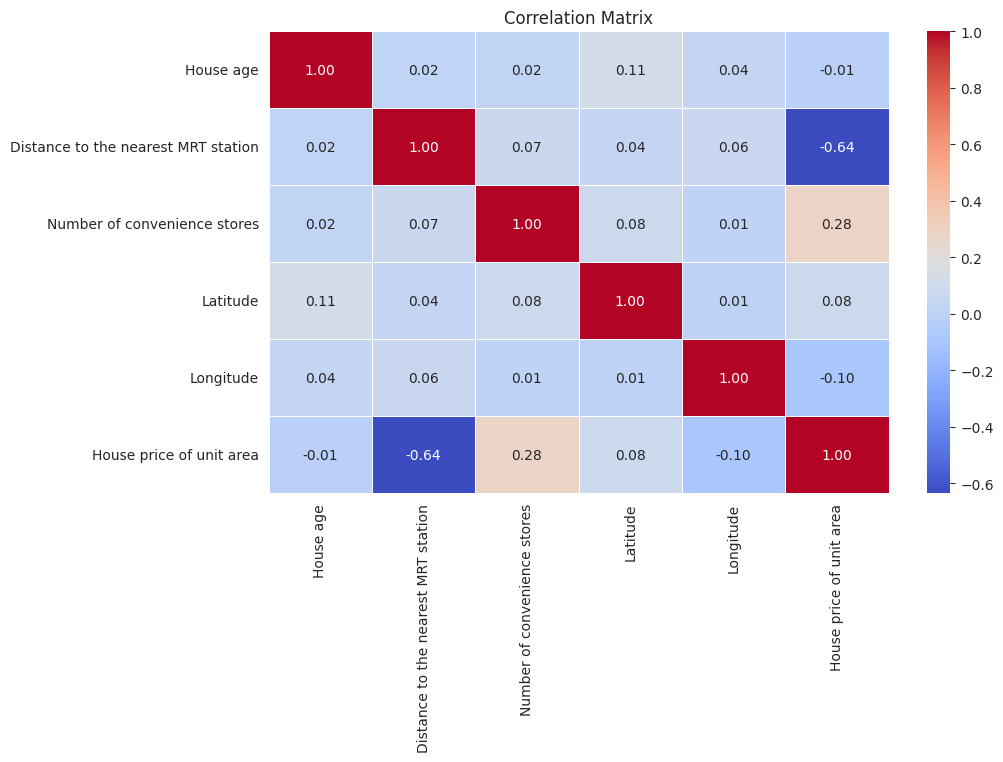
House age \
House age 1.000000
Distance to the nearest MRT station 0.021596
Number of convenience stores 0.021973
Latitude 0.114345
Longitude 0.036449
House price of unit area -0.012284
Distance to the nearest MRT station \
House age 0.021596
Distance to the nearest MRT station 1.000000
Number of convenience stores 0.069015
Latitude 0.038954
Longitude 0.064229
House price of unit area -0.636579
Number of convenience stores Latitude \
House age 0.021973 0.114345
Distance to the nearest MRT station 0.069015 0.038954
Number of convenience stores 1.000000 0.082725
Latitude 0.082725 1.000000
Longitude 0.013156 0.007754
House price of unit area 0.280763 0.081008
Longitude House price of unit area
House age 0.036449 -0.012284
Distance to the nearest MRT station 0.064229 -0.636579
Number of convenience stores 0.013156 0.280763
Latitude 0.007754 0.081008
Longitude 1.000000 -0.098626
House price of unit area -0.098626 1.000000
The correlation matrix provides quantified insights into how each variable is related to the others, especially with respect to the house price:
- House Age: This shows a very weak negative correlation with house price (-0.012), implying that age is not a strong predictor of price in this dataset.
- Distance to Nearest MRT Station: Has a strong negative correlation with house price (-0.637). It indicates that properties closer to MRT stations tend to have higher prices, which is a significant factor in property valuation.
- Number of Convenience Stores: Displays a moderate positive correlation with house price (0.281). More convenience stores in the vicinity seem to positively affect property prices.
- Latitude and Longitude: Both show a weak correlation with house prices. Latitude has a slight positive correlation (0.081), while longitude has a slight negative correlation (-0.099).
Overall, the most significant factors affecting house prices in this dataset appear to be the proximity to MRT stations and the number of convenience stores nearby. The geographical location (latitude and longitude) and the age of the house seem to have less impact on the price.
Now, let’s build a regression model to predict the real estate prices by using the Linear Regression algorithm:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Selecting features and target variable
features = ['Distance to the nearest MRT station', 'Number of convenience stores', 'Latitude', 'Longitude']
target = 'House price of unit area'
X = real_estate_data[features]
y = real_estate_data[target]
# Splitting the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Model initialization
model = LinearRegression()
# Training the model
model.fit(X_train, y_train)Now, let’s visualize the actual versus predicted values to assess how well our model is performing:
# Making predictions using the linear regression model
y_pred_lr = model.predict(X_test)
# Visualization: Actual vs. Predicted values
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_lr, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'k--', lw=2)
plt.xlabel('Actual')
plt.ylabel('Predicted')
plt.title('Actual vs. Predicted House Prices')
plt.show()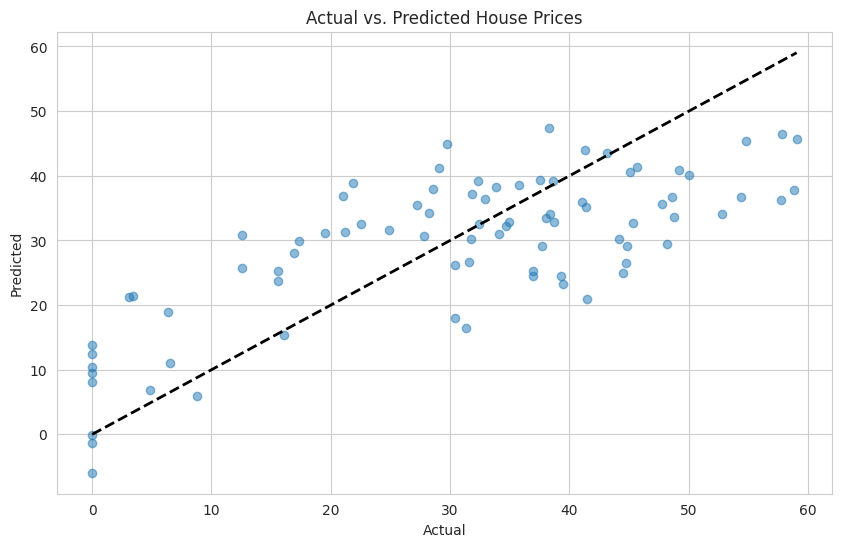
The diagonal dashed line represents where the actual and predicted values would be equal. Points close to this line indicate accurate predictions. From the plot, we can observe:
- Many points are close to the diagonal line, suggesting that the model makes reasonably accurate predictions for a significant portion of the test set.
- Some points are further from the line, indicating areas where the model’s predictions deviate more significantly from the actual values.
So, this is how we can predict real estate prices with Machine Learning using Python.
Summary
Real Estate Price Prediction is the process of estimating or forecasting the future prices of real estate properties, such as houses, apartments, or commercial buildings. The goal is to provide accurate property rates to buyers, sellers, investors, and real estate professionals to make informed decisions about real estate transactions. I hope you liked this article on Real Estate Price Prediction with Machine Learning using Python. Feel free to ask valuable questions in the comments section below.