Build an AI Agent to Master a Game
Do you know how AI opponents in video games seem to think, adapt, and sometimes, even outsmart you? The secret behind this is a powerful branch of AI called Reinforcement Learning. In fact, AI agents trained with these very principles have achieved superhuman performance in complex games like StarCraft II. In this article, I’ll explain how to build an AI agent from scratch using Python that learns to master a classic control game, known as the CartPole game.
What Exactly Is an AI Agent?
An AI agent is a program that can observe its environment, make decisions, and take actions to achieve a specific goal. It learns through trial and error, much like a person learning a new skill. It’s all done using:
- The Environment: The world the Agent lives in (in our case, the CartPole game).
- The Action: A move the Agent can make (e.g., push the cart left or right).
- The Reward: Feedback from the environment. A positive reward (like +1) for a good action, and a negative one (or no reward) for a bad one.
The Agent’s only goal is to maximize its total reward over time. It does this by learning a policy, a strategy for choosing the best action in any given situation. This learning process is called Reinforcement Learning.
Build an AI Agent to Master a Game using Python
Before our Agent can learn, it needs a world to interact with. We’ll use Gymnasium, a popular Python library that provides a vast collection of game environments for testing RL algorithms. We also need PyTorch to build the Agent’s brain.
First, let’s install these libraries:
pip install gymnasium torch
Step 1: Setting Up Our Playground
The game we’ll be tackling is CartPole-v1. The goal is simple:
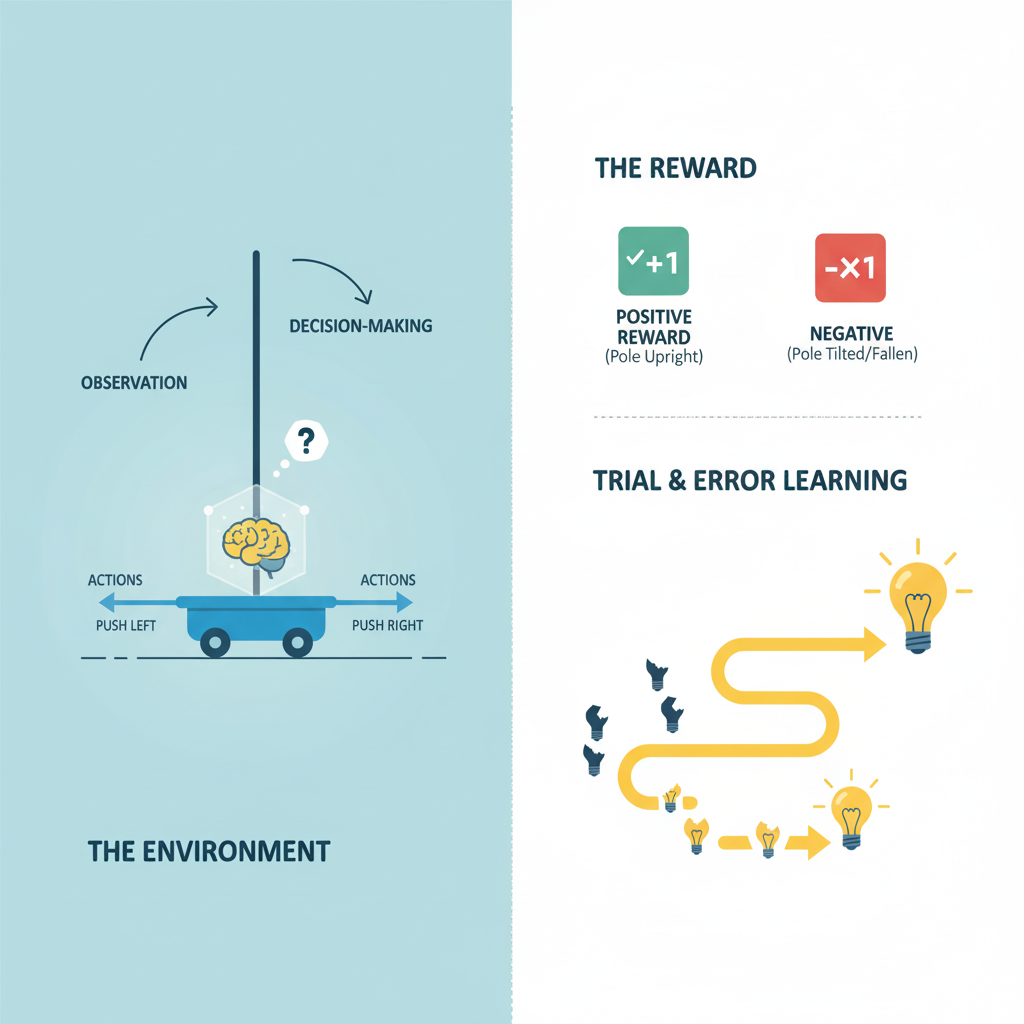
- A pole is attached to a cart, and our Agent must move the cart left or right to keep the pole balanced upright.
- For every moment it holds the pole balanced, it gets a reward of +1.
- If the pole falls over, the game ends.
Let’s see what this environment looks like. The following code initializes the CartPole game and has it take random actions for a few seconds:
import gymnasium as gym
import time
# load the CartPole environment
env = gym.make("CartPole-v1", render_mode="human")
# every game starts with a reset
state, info = env.reset()
# run the game for a short period
for _ in range(50):
# render the current frame
env.render()
# choose a random action (0 for push left, 1 for push right)
action = env.action_space.sample()
next_state, reward, terminated, truncated, info = env.step(action)
print(f"State: {state.shape}, Action: {action}, Reward: {reward}")
# update the state for the next loop
state = next_state
# if the game is over, reset it to start a new game
if terminated or truncated:
state, info = env.reset()
time.sleep(0.02) # slow down for visualization
# close the environment window
env.close()State: (4,), Action: 1, Reward: 1.0
State: (4,), Action: 1, Reward: 1.0
State: (4,), Action: 1, Reward: 1.0
State: (4,), Action: 0, Reward: 1.0
...
State: (4,), Action: 1, Reward: 1.0
State: (4,), Action: 1, Reward: 1.0
State: (4,), Action: 1, Reward: 1.0
If you run this, you’ll see the cart jittering around randomly and the pole falling over very quickly. This is our baseline, an unintelligent agent. Now, let’s build its brain.
Step 2: Building the Agent’s Brain with a Neural Network
Our Agent needs a way to decide which action is best in any given state. To do this, we’ll use a neural network called a Q-Network.
The network will take the game’s state as input (which for CartPole is a set of 4 numbers: cart position, cart velocity, pole angle, and pole angular velocity) and output a Q-value for each possible action (push left or push right). The higher the Q-value, the more suitable the network perceives that action to be for the current state.
Here’s how we define this network using PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
class QNetwork(nn.Module):
"""
Neural Network to approximate the Q-value function.
"""
def __init__(self, state_size, action_size):
"""
Initializes the network layers.
:param state_size: The number of features in the game state (e.g., 4 for CartPole).
:param action_size: The number of possible actions (e.g., 2 for CartPole).
"""
super(QNetwork, self).__init__()
self.network = nn.Sequential(
nn.Linear(state_size, 128),
nn.ReLU(), # activation function
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_size)
)
def forward(self, state):
"""
Defines the forward pass of the network.
It takes a state and returns the Q-values for each action.
"""
return self.network(state)This simple network is the core of our Agent’s intelligence. It will learn to map game states to smart actions.
Step 3: Creating the Agent’s Logic
Now we wrap our Q-Network inside a DQNAgent class. This class will handle all the logic for interacting with the environment, learning from experiences, and making decisions. Here are its three key jobs:
- Remembering Experiences: The Agent doesn’t just learn from its last move. It stores thousands of past experiences (state, action, reward, next_state, done) in a replay buffer. It then learns from random samples of these memories, which is a much more stable way to train.
- Deciding a Move: To choose an action, the Agent uses an epsilon-greedy strategy. Most of the time, it exploits its knowledge by picking the action its network predicts is best. But sometimes (controlled by a value called epsilon), it explores by taking a random action to discover potentially better strategies. Early on, the Agent explores a lot, but as it gets smarter, epsilon decreases, and it relies more on what it has learned.
- Getting Smarter: This is the core of the learning process. The Agent compares the Q-value its network expects for an action with a more accurate target Q-value calculated from the actual reward and outcome. The difference between the expected and target values is the loss. The Agent then updates its network to minimize this loss, slowly making its predictions closer to reality.
Here’s how to implement the DQN Algorithm for creating the Agent’s logic:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
import random
from collections import deque, namedtuple
# Hyperparameters
BUFFER_SIZE = 10000 # replay buffer size
BATCH_SIZE = 64 # minibatch size for training
GAMMA = 0.99 # discount factor for future rewards
LR = 5e-4 # learning rate
UPDATE_EVERY = 4 # how often to update the network
# use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class DQNAgent():
"""Interacts with and learns from the environment."""
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
# Q-Network
self.qnetwork_local = QNetwork(state_size, action_size).to(device)
self.optimizer = optim.Adam(self.qnetwork_local.parameters(), lr=LR)
# replay memory
self.memory = ReplayBuffer(action_size, BUFFER_SIZE, BATCH_SIZE)
# initialize time step
self.t_step = 0
def step(self, state, action, reward, next_state, done):
# save experience in replay memory
self.memory.add(state, action, reward, next_state, done)
# learn every UPDATE_EVERY time steps.
self.t_step = (self.t_step + 1) % UPDATE_EVERY
if self.t_step == 0:
# if enough samples are available in memory, get random subset and learn
if len(self.memory) > BATCH_SIZE:
experiences = self.memory.sample()
self.learn(experiences, GAMMA)
def act(self, state, eps=0.):
"""Returns actions for given state as per current policy."""
state = torch.from_numpy(state).float().unsqueeze(0).to(device)
self.qnetwork_local.eval() # set network to evaluation mode
with torch.no_grad():
action_values = self.qnetwork_local(state)
self.qnetwork_local.train() # set network back to training mode
# epsilon-greedy action selection
if random.random() > eps:
return np.argmax(action_values.cpu().data.numpy())
else:
return random.choice(np.arange(self.action_size))
def learn(self, experiences, gamma):
"""Update value parameters using given batch of experience tuples."""
states, actions, rewards, next_states, dones = experiences
# get max predicted Q-values for next states from the network
Q_targets_next = self.qnetwork_local(next_states).detach().max(1)[0].unsqueeze(1)
# compute Q targets for current states
# target = reward + gamma * Q_next (if not done)
Q_targets = rewards + (gamma * Q_targets_next * (1 - dones))
# get expected Q values from local model
Q_expected = self.qnetwork_local(states).gather(1, actions)
# compute loss
loss = F.mse_loss(Q_expected, Q_targets)
# minimize the loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Replay Buffer
class ReplayBuffer:
"""Fixed-size buffer to store experience tuples."""
def __init__(self, action_size, buffer_size, batch_size):
self.memory = deque(maxlen=buffer_size)
self.batch_size = batch_size
self.experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"])
def add(self, state, action, reward, next_state, done):
"""Add a new experience to memory."""
e = self.experience(state, action, reward, next_state, done)
self.memory.append(e)
def sample(self):
"""Randomly sample a batch of experiences from memory."""
experiences = random.sample(self.memory, k=self.batch_size)
states = torch.from_numpy(np.vstack([e.state for e in experiences if e is not None])).float().to(device)
actions = torch.from_numpy(np.vstack([e.action for e in experiences if e is not None])).long().to(device)
rewards = torch.from_numpy(np.vstack([e.reward for e in experiences if e is not None])).float().to(device)
next_states = torch.from_numpy(np.vstack([e.next_state for e in experiences if e is not None])).float().to(device)
dones = torch.from_numpy(np.vstack([e.done for e in experiences if e is not None]).astype(np.uint8)).float().to(device)
return (states, actions, rewards, next_states, dones)
def __len__(self):
"""Return the current size of internal memory."""
return len(self.memory)Over thousands of these minor updates, the Q-Network’s predictions become incredibly accurate, and the Agent’s policy becomes very effective.
Step 4: The Training Loop
Now we bring everything together in a training loop. We’ll set some hyperparameters, like the number of episodes to train for and the epsilon decay rate, and then set the Agent loose in the environment:
import gymnasium as gym
# Initialize Environment and Agent
env = gym.make("CartPole-v1")
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
agent = DQNAgent(state_size=state_size, action_size=action_size)
# Training Hyperparameters
n_episodes = 2000 # max number of training episodes
max_t = 1000 # max number of timesteps per episode
eps_start = 1.0 # starting value of epsilon
eps_end = 0.01 # minimum value of epsilon
eps_decay = 0.995 # multiplicative factor for decreasing epsilon
def train():
scores = [] # list containing scores from each episode
scores_window = deque(maxlen=100) # last 100 scores
eps = eps_start # initialize epsilon
for i_episode in range(1, n_episodes + 1):
state, info = env.reset()
score = 0
for t in range(max_t):
action = agent.act(state, eps)
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
agent.step(state, action, reward, next_state, done)
state = next_state
score += reward
if done:
break
scores_window.append(score)
scores.append(score)
# decrease epsilon
eps = max(eps_end, eps_decay * eps)
print(f'\rEpisode {i_episode}\tAverage Score: {np.mean(scores_window):.2f}', end="")
if i_episode % 100 == 0:
print(f'\rEpisode {i_episode}\tAverage Score: {np.mean(scores_window):.2f}')
# check if the environment is solved
if np.mean(scores_window) >= 195.0:
print(f'\nEnvironment solved in {i_episode-100:d} episodes!\tAverage Score: {np.mean(scores_window):.2f}')
# save the trained model's weights
torch.save(agent.qnetwork_local.state_dict(), 'checkpoint.pth')
break
return scores
scores = train()
env.close()Episode 100 Average Score: 19.83
Episode 200 Average Score: 66.43
Episode 261 Average Score: 196.76
Environment solved in 161 episodes! Average Score: 196.76
Watching the output, you’ll see the average score start low and steadily climb. In the provided test run, the Agent achieved an average score of 196.76 after just 261 episodes, solving the environment in only 161 learning episodes!
Watching Our AI Agent Play the Game
Training is done. We’ve saved our Agent’s brain. Now, let’s load those trained weights and watch our Agent play flawlessly:
# Testing the AI Agent
# Step 1: Initialize the Environment and Agent
env = gym.make("CartPole-v1", render_mode="human")
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# create an agent
agent = DQNAgent(state_size=state_size, action_size=action_size)
# Step 2: Load the Trained Weights
agent.qnetwork_local.load_state_dict(torch.load('checkpoint.pth'))
# Step 3: Watch the Smart Agent Play
num_episodes_to_watch = 10
for i in range(num_episodes_to_watch):
# reset the environment to get the initial state
state, info = env.reset()
done = False
episode_reward = 0
print(f"--- Watching Episode {i+1} ---")
while not done:
# render the environment
env.render()
# choose the best action using the trained network (epsilon=0)
action = agent.act(state)
# perform the action in the environment
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
# update the state
state = next_state
episode_reward += reward
# add a small delay to make it watchable
time.sleep(0.02)
print(f"Score for Episode {i+1}: {episode_reward}")
# close the environment window
env.close()--- Watching Episode 1 ---
Score for Episode 1: 500.0
--- Watching Episode 2 ---
Score for Episode 2: 500.0
--- Watching Episode 3 ---
Score for Episode 3: 460.0
--- Watching Episode 4 ---
Score for Episode 4: 420.0
--- Watching Episode 5 ---
Score for Episode 5: 498.0
--- Watching Episode 6 ---
Score for Episode 6: 438.0
--- Watching Episode 7 ---
Score for Episode 7: 410.0
--- Watching Episode 8 ---
Score for Episode 8: 451.0
--- Watching Episode 9 ---
Score for Episode 9: 388.0
--- Watching Episode 10 ---
Score for Episode 10: 419.0
When you run this code, you’ll see the AI Agent expertly balancing the pole, often for hundreds of steps. The final scores speak for themselves, with the Agent consistently achieving high scores, like 500, 460, and 498!
Final Words
So, in this article, you learned to build a fully trained AI agent to master a game. We didn’t just use a pre-built model; we built the Agent’s memory, its decision-making logic, and its learning mechanism from the ground up.
This is the foundation. The same principles of states, actions, rewards, and learning from experience are used to build AI Agents that can master far more complex challenges, from a self-driving car navigating a city to an AI champion in a professional video game.